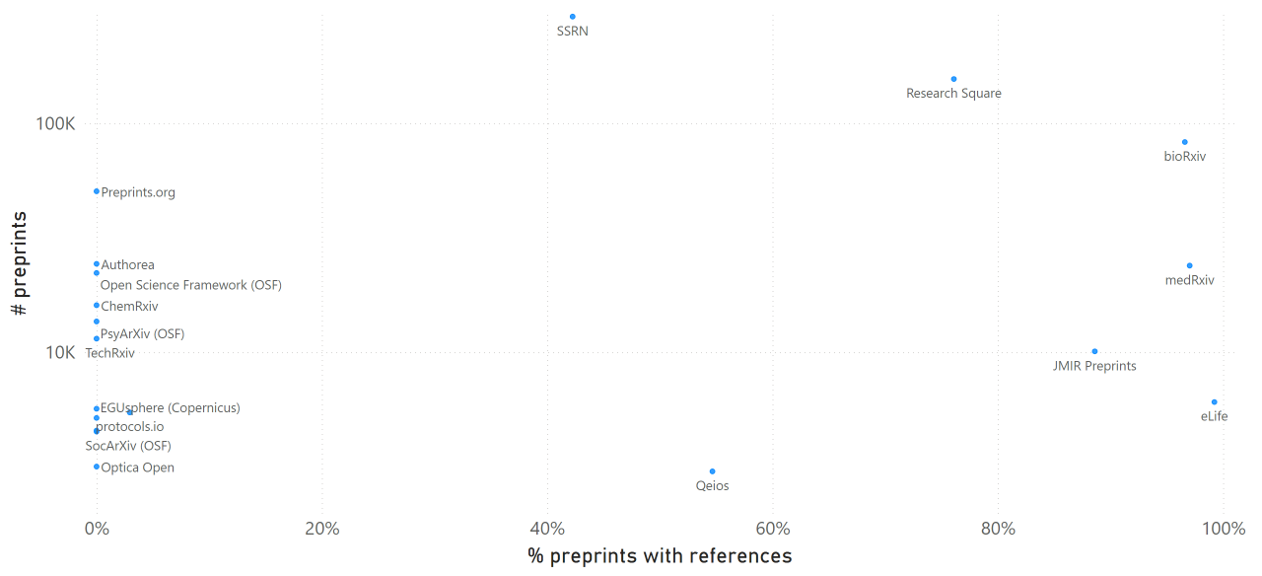
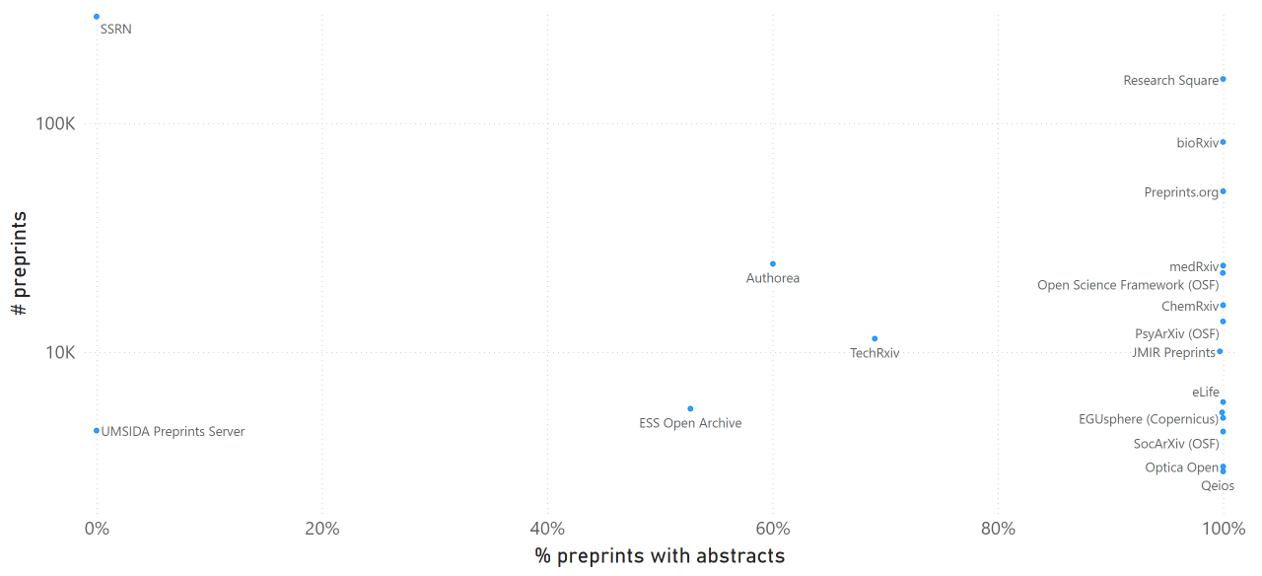
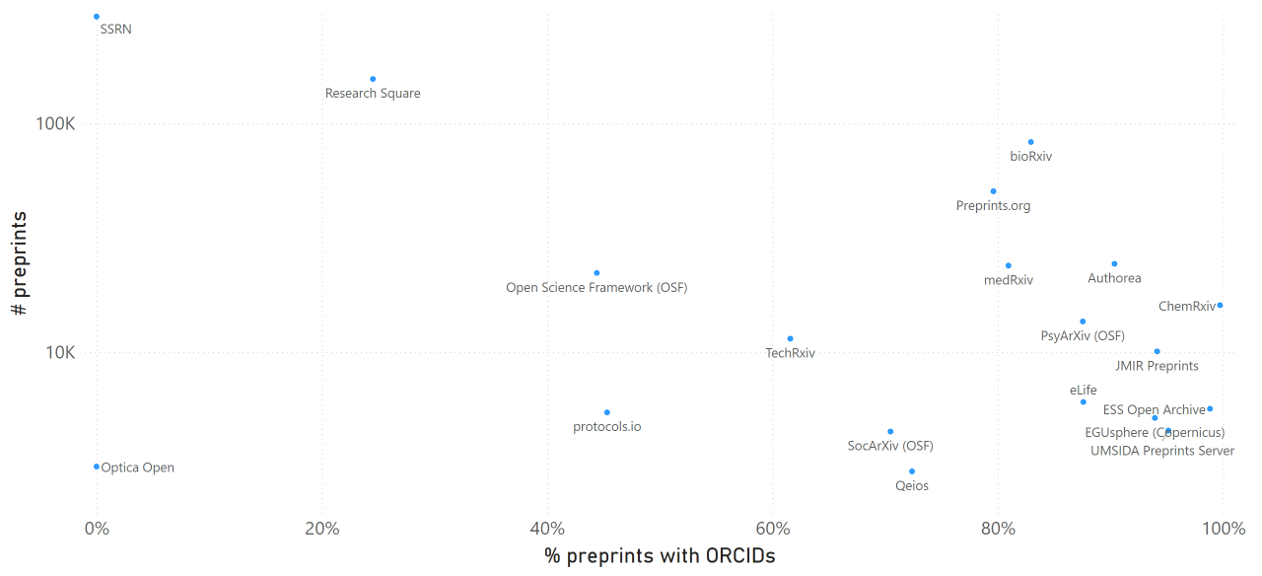
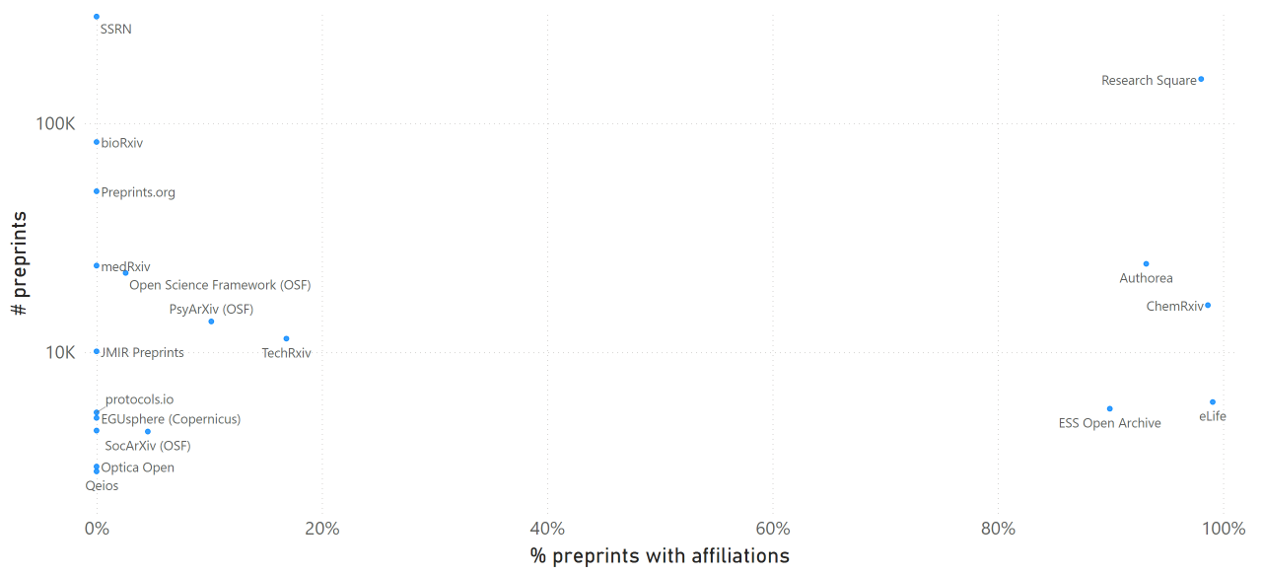
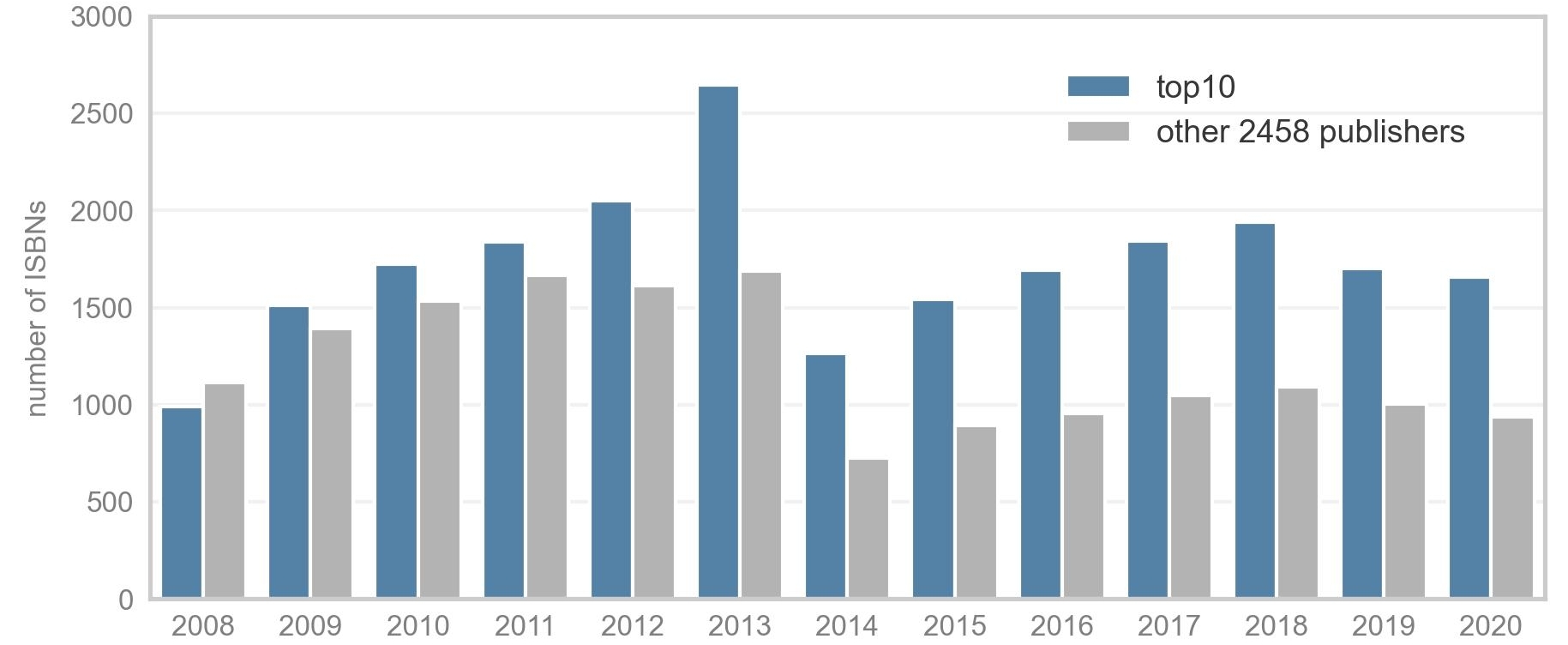
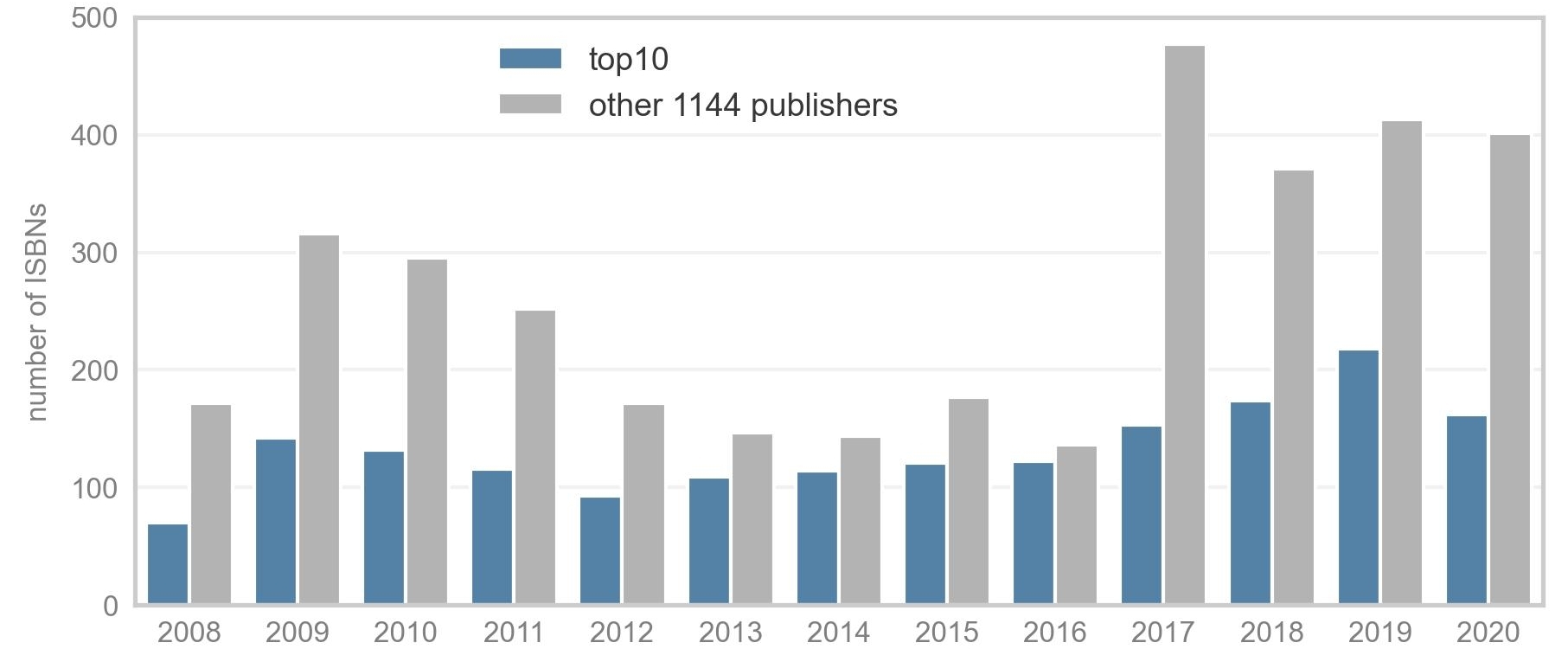
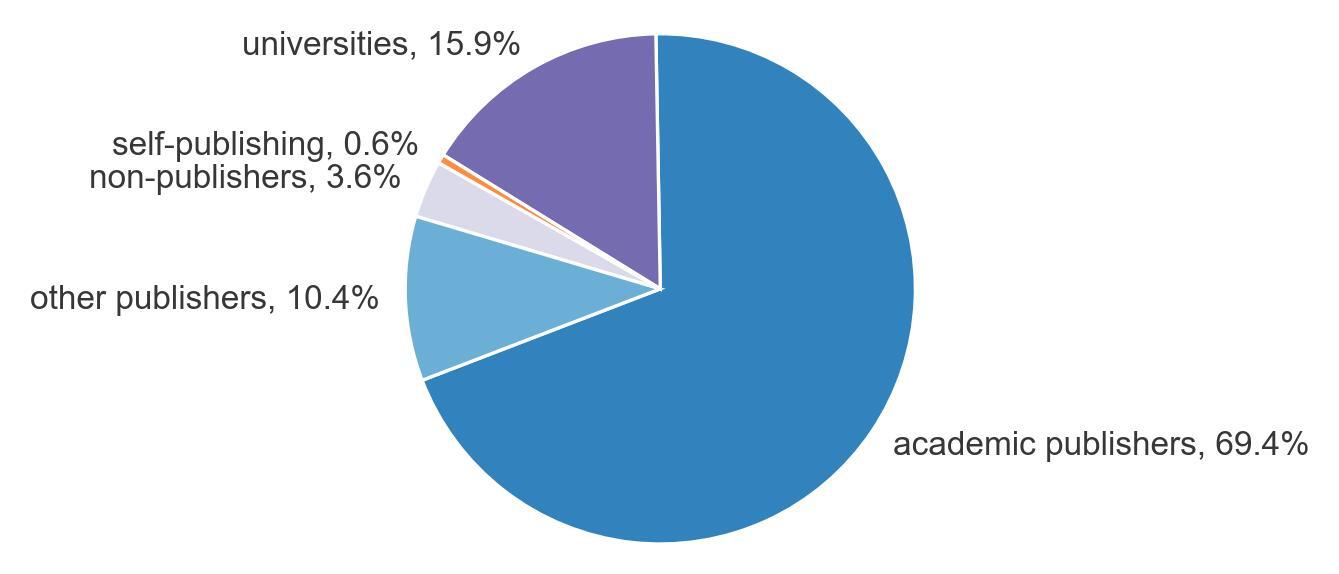
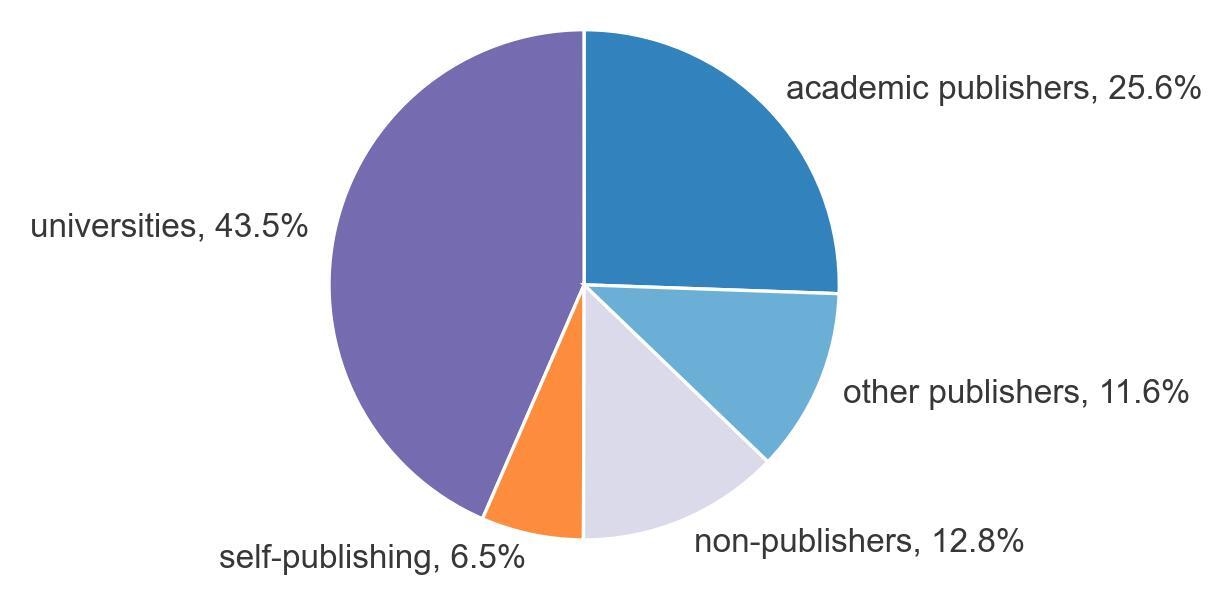
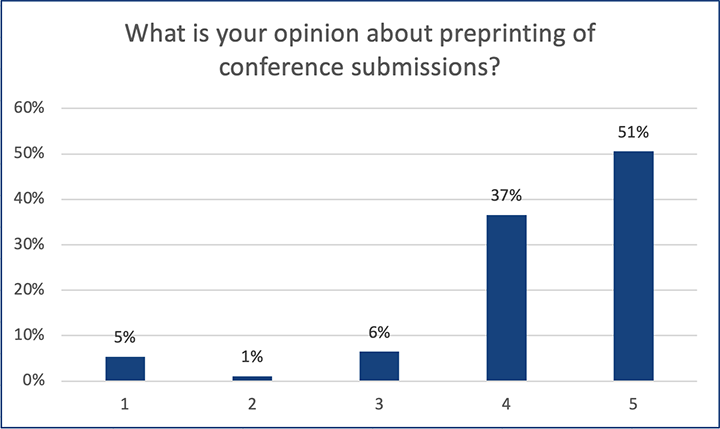
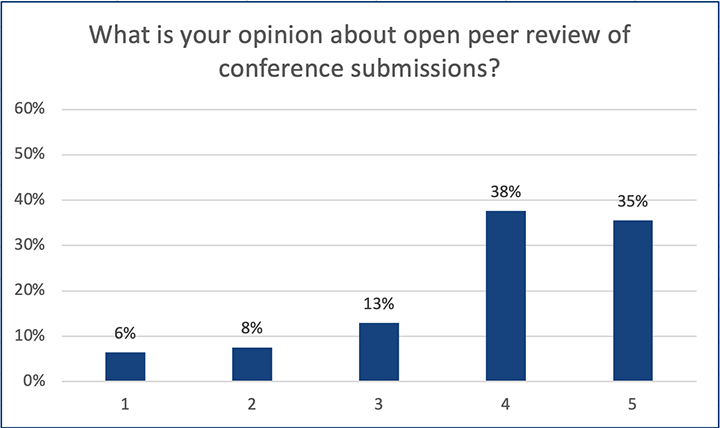
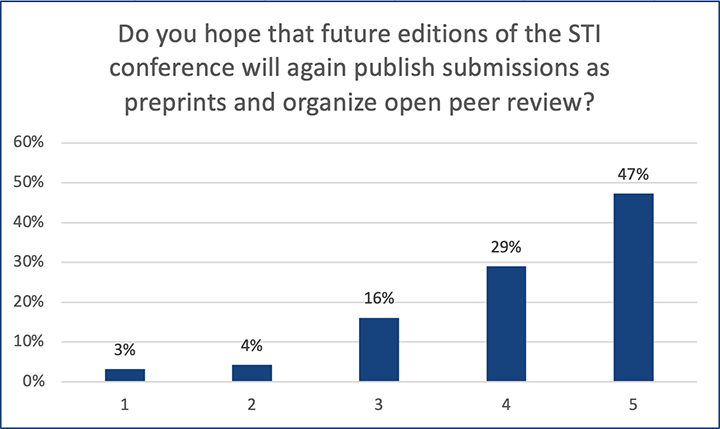
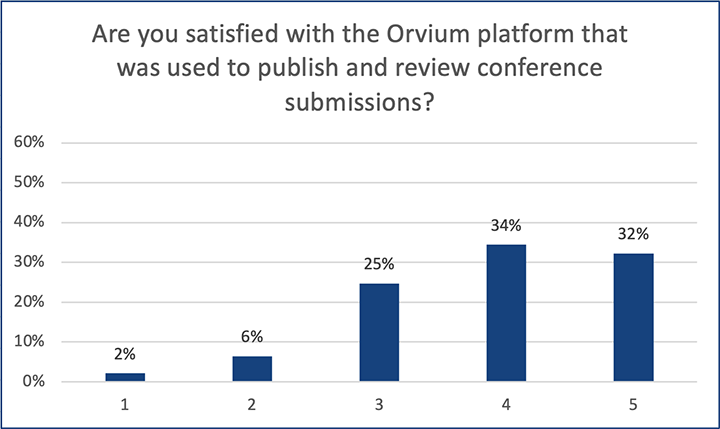
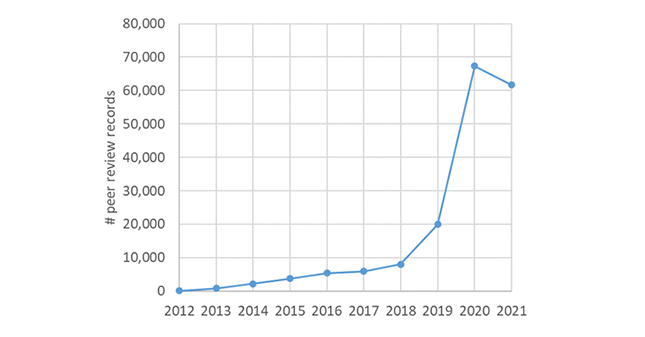
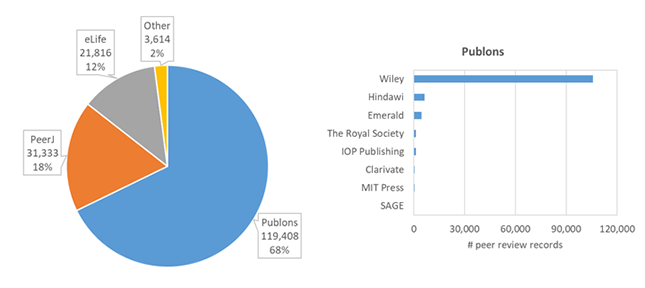
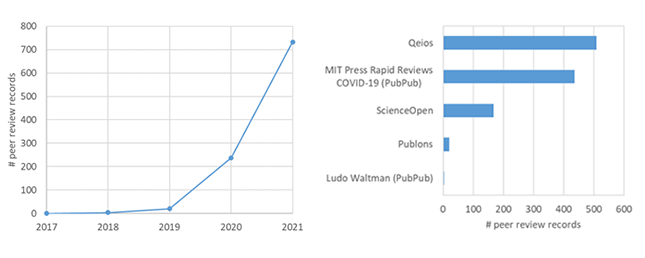
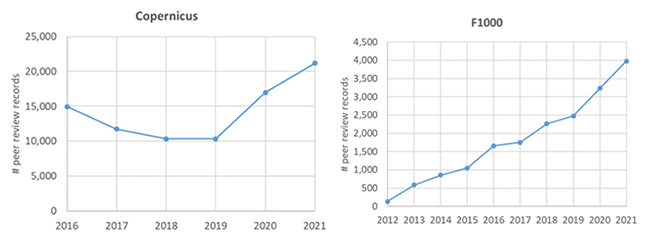
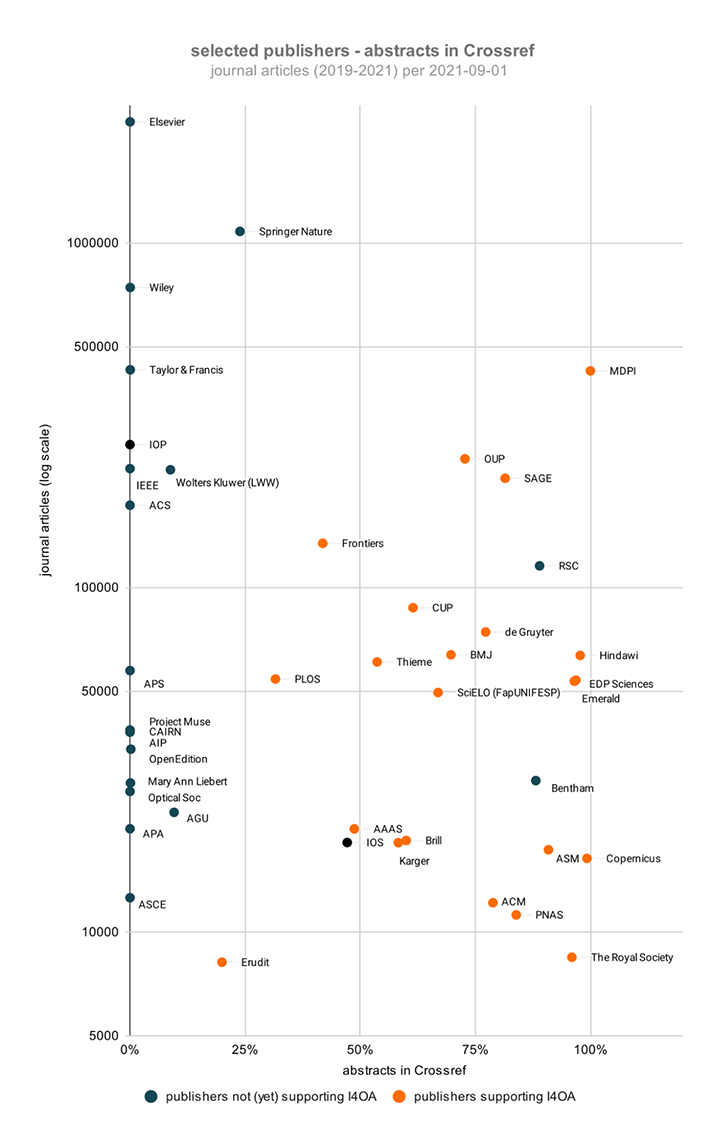
This post is based on the following manuscript, currently under review: Tiokhin, L., Panchanathan, K., Lakens, D., Vazire, S., Morgan, T., & Zollman, K. (Preprint). Honest signaling in academic publishing, and is also published in the author's blog author's blog).
If you asked me, “Leo — why did you pursue a career in science?”, I’m not sure that I could give you a good answer. Maybe it had something to do with the whole being “curious about the nature of reality” thing. Maybe it’s because I’m stubborn and argumentative, and I thought that academic science rewarded these traits. Or maybe I just liked the independence — the chance to study whatever I wanted and actuallyget paid for it.
I can, however, think of one thing that definitely wasn’t a reason for getting into science: writing up my research in the sexiest way possible, submitting it to high-impact journals, and hoping to convince some editor to publish it and validate my sense of self-worth (and slightly increase my chances of getting a grant or permanent position some day).
I mean, my memory isn’t great, but I’m pretty sure that wasn’t part of the equation.
The reality is that many of us are idealistic when we get into science. Then, little by little, we learn the rules of the game. We learn that certain types of results, such as those that are novel and statistically significant, are valued more than others. We learn that scientists prefer clean, compelling narratives over honest descriptions of mixed findings and protocol failures. And we learn that our scientific worth is determined by whether we publish in certain journals, such as those with a high impact-factor.
Once we learn the rules, we begin to play (or we just get fed up and leave ). After all, nobody likes to lose, even if it’s just a game.
In this post, I’d like to focus on one game that scientists play: writing up and submitting papers for publication. I’ll try to convince you that, given the way this game is set up, scientists are incentivized to deceive journals about the quality of their work.
I’ll also try to convince you that all hope is not lost. Even if we accept that scientists “play the game”, we can change the rules to promote a more “honest” publishing system. Along the way, we’ll learn a bit of signaling theory, and I’ll even throw in a Ghostbusters reference or two.
Academic journals are vulnerable to deception.
Why? Well, there are two interrelated reasons.
- There are information asymmetries between scientists and journals.
- There are conflicts of interest between scientists and journals.
Scientists know every little detail about their research — how many experiments they ran, how many dependent variables they measured, all the ways they analyzed their data, how their hypotheses changed throughout the research process, etc. But a journal only sees the final paper. So, there’s an information asymmetry - scientists have more information about some aspects of their work (for example, things related to its “quality”) than do journals.
All else equal, scientists have incentives to publish each paper in the highest-ranking journal possible (even if a paper isn’t very good). But high-ranking journals don’t want to publish every paper — they want a subset of papers that meet their publication criteria. These might be papers with compelling evidence, novel results, important theoretical contributions, or whatever. This creates a conflict of interest, in the game-theoretic sense — a scientist may benefit by getting a methodologically sloppy, p-hacked paper published in a high-ranking journal, but the high-ranking journal would prefer not to publish this paper (all else equal).
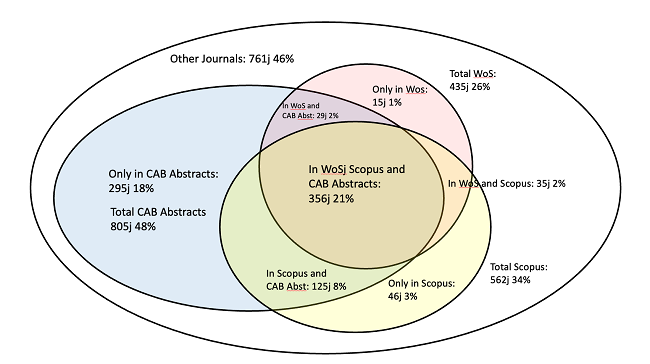
These factors make journals vulnerable to deception. This vulnerability exists along any dimension where there are information asymmetries and conflicts of interest. Let’s focus on research “quality” for now, because that’s a case where the information asymmetries and conflicts of interest are clear (see Simine Vazire’s nice paper about this in the context of quality uncertainty and trust in science).
Aside: I’m going to use a behavioral definition of deception — an act that transmits information that doesn’t accurately (i.e., honestly) represent some underlying state (and was designed to do so). This sidesteps the whole “is it conscious or not” business. It also gets closer to how biologists think of “deceptive signals”, which will become relevant later.
Why should we care if scientists attempt to “deceive” journals by submitting low-quality work to high-ranking journals? At least 3 reasons.
- It wastes editors’ and reviewers’ time.
- Peer review sucks. So, low-quality papers “slip through the cracks” and onto the pages of high-ranking journals (it’s trivially easy to find example after example after example of this). This lowers any correlation between journal rank and research quality, which isn’t ideal because, for better or worse, scientists use journal rank as a proxy for “quality” (hint: it’s worse).
- If low-quality research takes less time than high-quality research but still gets published in high-ranking journals, then scientists have less incentive to do high-quality work. This can generate adverse selection: high-quality work is driven out of the market, until low-quality garbage is all that remains (you can also think of the related “Natural Selection of Bad Science”, where low-quality science spreads even if scientists don’t strategically adjust their methods).
So, it’d be nice if we could solve this problem somehow.
If there’s something strange…in your neighborhood.
If there’s something weird…and it don’t look good.
If you’re seeing p-hacking…when you look under the hood.
If you’re reading shitty papers…and it’s ruining your mood.
Who you gonna call?
Of course, deception isn’t unique to academic publishing — whenever there are information asymmetries and conflicts of interest, there are incentives to deceive.
Consider a biological example. A mama bird brings food back to her nest and must decide which chick to feed. Mama prefers to feed the hungriest chick and so benefits from knowing how much food each chick needs. But each chick may want the food for itself. So, even though Mama would benefit if the chicks honestly communicated their level of hunger, each chick may benefit by deceiving Mama and claiming to be the hungriest.
How can honest communication exist when there are incentives for deception? Why don’t communication systems just become filled with lies and break down?
It turns out that economists and biologists have been interested in this question for a long time. And so, there’s a body of formal theory — Signaling Theory — dedicated to this and related problems (I’m more familiar with biological signaling theory, so I’ll focus on that).
This is good news.
Why? Because it means that signaling theory can potentially provide us with “tools for thinking” about how to deal with deception in academic publishing.
Who you gonna call? Signaling theory!
I tried ¯\_(:/)_/¯
One insight from signaling theory is that “honest signaling” is possible if the costs or benefits of producing a signal are different for different “types” of individuals. Think back to Mama bird and her chicks. Imagine that there are two types of chicks — starving and kinda-hungry. Both chicks benefit from getting food. But the benefit is larger for the starving chick, because it needs the food more.
If signaling (e.g., loudly begging Mama bird for food) has no cost, then none of this matters - both chicks will signal because they benefit from the food. But what if the signal is costly? Then, a chick will only signal if the benefits of getting the food outweigh the cost of the signal. This is where it gets interesting. Because the starving chick benefits more from the food than the kinda-hungry chick, if a signal is costly enough, then it’s only worth paying this cost if a chick is truly starving. So, in a world of magical payoff-maximizing chicks and where begging is just costly enough, only the starving chicks would be doing the begging.
Boom — honest signaling.
This is what’s known as a situation of differential benefits — both chicks pay the same cost when begging, but receive different payoffs from getting fed. Another way to get honest signaling is via differential costs. The idea is similar, except that different types pay different costs for the same signal. For example, maybe a good skateboarder can get away with doing a roof drop to show how cool they are, but a bad skateboarder would break their legs. The key is that producing a signal must only be worth it for some types of individuals (there are also other ways to get honest signaling that I won’t get into here - check out (1) and (2) if interested).
Now let’s apply these insights to academic publishing. Say that we want a system where scientists don’t submit every paper to high-ranking journals, thinking that they might as well “give it a shot”. Instead, say that we want scientists to “honestly” submit high-quality papers to high-ranking journals and low-quality papers to low-ranking journals. What reforms would move us towards this outcome?
My co-authors and I go through a bunch of these in our paper. Here, I’ll list a few that I think are most interesting.
Publishing inefficiencies serve a function.
We often complain about publishing inefficiencies, like long review times, arbitrary formatting requirements, and high financial costs to publication. But, as the signaling example shows, inefficiencies can serve a function: the costs associated with publishing reduce the incentive to submit low-quality research to high-ranking journals. Economists have known this for a long time (1, 2). Just think of what would happen if Nature and Science made their submission process as low-cost as possible (e.g., no submission costs, formatting requirements, or cover letters; guaranteed reviews within 48 hours). They’d get flooded with (even more) shitty submissions.
The point isn’t that inefficiencies are “good for science”. It’s that we should keep in mind that removing inefficiencies will create collateral damage, and we need to weigh this damage against the benefits of a more efficient publishing system. I see a lot of room for work on this and related problems: what functions do inefficiencies serve and how can we optimally structure inefficiencies to generate the best outcomes for science?
Creating differential benefits.
For differential benefits, the key is to create a system where there are larger benefits for submitting or publishing high-quality versus low-quality papers in high-ranking journals.
Some ways to do this are intuitive. We can improve peer-review (which makes it easier to tell good work from bad). We can mandate transparent research practices (same function).
Another idea is to reduce the benefits associated with publishing low-quality work in high-ranking journals. I see a few potential approaches here. We could target high-ranking publications for direct replication or preferentially scrutinize them for questionable research practices, statistical/mathematical errors, and problems with study design. This would be a post-publication differential benefits approach. Then, we would need to make sure that scientists receive lower benefits for publishing bad work in high-ranking journals. Possibilities include financial penalties, fewer citations for the published paper, or reputational damage (maybe the journal refuses to accept the scientist’s future submissions for some amount of time, or maybe other journals raise their bar for publishing that scientist’s future papers).
Creating differential costs.
For differential costs, the key is to create a system where there are larger costs for submitting or publishing low-quality versus high-quality papers in high-ranking journals.
One way to do this is to create costs to resubmission. When submission and resubmission is cheap and easy, scientists are incentivized to submit all papers to high-ranking journals, because scientists don’t lose anything when they get rejected. Resubmission costs solve this problem by making rejection costly. If low-quality submissions are more likely to be rejected, then resubmission costs will work. Of course, this would be another inefficiency in the publication process, which is something we’d need to take into account.
If we wanted to go this route, there are a few possibilities. Editors could wait some time before sending “reject” decisions. This would cause disproportionate delays for low-quality submissions. If papers had pre-publication DOI’s and their submission histories could be tracked, journals could refuse to evaluate papers that had been resubmitted too quickly. Or authors could “pay” for submissions by having to peer review N other papers for each submission.
Something else that could work would be to make peer-review and editorial decisions openly available, even for rejected papers. I like this idea (though it does have some issues, like generating information cascades). One nice thing is that making peer-review and editorial decisions openly available would mean that less information gets lost throughout the submission process (because prior reviews don’t just disappear into the darkness). And if low-quality papers receive more negative reviews, on average, then scientists will have fewer incentives to “try out” submitting to a high-impact journal, because negative reviews would follow the paper to future journals (and would eventually be seen by readers).
Other ways to increase differential costs could be to target the submission process. For example, authors could pay a submission fee (as is the case for some journals in Economics, Accounting, and Finance) but get refunded if the paper is deemed to be sufficiently high quality. This could even be incremental — bigger fees when there’s a bigger difference between the journal’s minimum standards and the quality of the submission.
Limiting the number of submissions (or rejections) per paper.
This will also work (but because it creates opportunity costs). I’ll discuss this idea in more detail in a future post. If you’re interested, check out the paper, which goes into more detail.
Epic inspiring ending.
This is where I’m supposed to bring everything together, throw in an inspirational quote, and make a final Ghostbusters reference, to make you think, “well isn’t he clever.” Must. Validate. Sense. Of. Self. Worth.
Instead, a few thoughts.
I’m not really a fan of the current publishing system, using journal rank as a proxy for quality, publishing inefficiencies, and so on. I hate the game, and resent the fact that I need to play it to have a successful academic career. I’m open to overhauling the system completely (e.g., getting rid of journals) if we get solid evidence that this would be better. But we’re not quite there yet. For now, we’re stuck. Journals and rankings. Information asymmetries. Conflicts of interests. So if we’re going to play this game, then we should consider how we can change the rules to produce better outcomes.
As we think about changing these rules, we could do worse than to add “differential costs” and “differential benefits” to our conceptual toolkits. These ideas have proven their worth in biology, and will likely be of use to us, even outside the context of academic publishing.
Want to prevent scientists from submitting grant applications when their ideas are bad or infeasible? Make grant submission more costly for bad proposals. John Ioannidis suggested a version of this with the “provocative” idea that grants be “...considered negatively unless one delivers more good-quality science in proportion”. Producing good-quality science is harder if your proposal was bad or infeasible. Boom — differential costs. Alternatively, as suggested for academic publishing, there could be submission fees that are refunded if a grant proposal meets some quality threshold.
We should keep in mind that many of the ideas here could exacerbate inequalities between individuals with more or less resources, such as early-career researchers and scientists in developing countries. This is a concern (though there are solutions, such as making submission costs conditional on scientists’ ability to pay them). The paper discusses this a bit.
Finally, we should keep our eyes open for what we can learn from other disciplines. The fact that signaling theory is useful for thinking about academic publishing is just the tip of the iceberg. As one example, while working on our paper, my co-authors and I discovered a huge literature in economics that addresses these same problems (and where people have come to many of the same conclusions about how to improve academic publishing). We review some of this work in the paper. For a nice, non-mathy introduction, check out this paper.
So, what now?
You could read our paper. That’s an ok start. You could give me and my co-authors all of your money, so that we can figure out how to make publishing more efficient and reliable. That benefits us, but probably isn’t in your best interest. You could immerse yourself in the literature on signaling in biology and publishing reform in economics. That may or may not be useful for you though, and it’s pretty costly.
I think I’ve got a better idea.
If you’re all alone
Pick up the phone
And call…
Thanks to Anne Scheel, Daniel Lakens, Kotrina Kajokaite & Karthik Panchanathan for feedback on an earlier version of this post.
]]>