




Opening up the CWTS Leiden Ranking: Toward a decentralized and open model for data curation
Today, CWTS released the Open Edition of the Leiden Ranking. This blog post discusses the data curation approach taken in this fully transparent edition of the Leiden Ranking.
The need to increase the transparency of university rankings is widely recognized, for instance in the ten rules for ranking universities that we published in 2017, in the work done by the INORMS Research Evaluation Working Group, and also in a recent report by a Dutch expert group on university rankings (co-authored by one of us). It is therefore not surprising that the announcement of the Open Edition of the CWTS Leiden Ranking in 2023 got considerable attention and triggered lots of highly supportive responses.
The announcement also led to questions about the quality of the data used in the Leiden Ranking Open Edition, in particular the affiliation data for linking publications to universities. In this post, we address these questions by distinguishing between two models for curating affiliation data: the centralized and closed model and the decentralized and open model. While the traditional Leiden Ranking relies primarily on the centralized and closed model, the Open Edition released today represents a movement toward the decentralized and open model.
The centralized and closed model for data curation
In the centralized and closed model, a central actor in the system takes responsibility for data curation. The data is closed. It can be accessed only by selected users, who typically need to pay to get access.
The traditional Leiden Ranking, based on closed data from Web of Science, takes a mostly centralized approach to curating affiliation data. While some basic data curation (standardizing affiliation strings) is performed by Web of Science, the bulk of the work is done by CWTS (determining which standardized affiliation strings refer to the same ‘unified organizations’). Because Web of Science data is closed, CWTS is unable to share the curated data. This means there is no easy way for universities to check the quality of the data.
The decentralized and open model for data curation
In the decentralized and open model, data curation takes place in a decentralized way. Different actors in the system take responsibility for different parts of the data curation process. All data is fully open, which facilitates collaboration between the different actors.
The Leiden Ranking Open Edition, based on open data from OpenAlex, takes a mostly decentralized approach to curating affiliation data. Contributions to the data curation process are made by a number of different actors:
- The Research Organization Registry (ROR) provides ROR IDs for research organizations.
- Publishers deposit publication metadata, including author affiliations, to Crossref and PubMed.
- Crossref and PubMed make publication metadata, including author affiliations, openly available.
- OpenAlex ingests author affiliations from Crossref and PubMed. It performs web scraping to obtain missing author affiliations. It then uses a machine learning algorithm to map affiliation strings to ROR IDs.
- CWTS maps ROR IDs to ‘unified organizations’. For instance, the ROR IDs of Leiden University (https://ror.org/027bh9e22) and Leiden University Medical Center (https://ror.org/05xvt9f17) are both mapped to Leiden University, since the Leiden Ranking considers Leiden University Medical Center to be part of Leiden University.
The above actors all share data openly. This enables research organizations to check the quality of the data and to contribute to the data curation process by reporting data quality problems to the relevant actors (e.g., ROR, OpenAlex, or CWTS).
How much difference does it make?
Over the past months, many people have asked us to what extent results obtained from the data curation approach taken in the Leiden Ranking Open Edition are different from results obtained from the data curation approach of the traditional Leiden Ranking. To answer this question, we match publications in OpenAlex and Web of Science based on DOIs and we then use this matching to compare the results obtained using the two data curation approaches. Our focus is on publications from the period 2018-2021.
We first compare the overall set of publications included in the traditional Leiden Ranking to the overall set of publications included in the Open Edition. The traditional Leiden Ranking includes all publications in Web of Science that are indexed in the Science Citation Index, the Social Sciences Citation Index, or the Arts & Humanities Citation Index, that are classified as research article or review article, and that meet a number of additional criteria. Likewise, the OpenEdition includes all publications in OpenAlex that are classified as article or book chapter, that have affiliation and reference metadata (for some publications this metadata is missing in OpenAlex), and that meet additional criteria similar to those used in the traditional Leiden Ranking. Figure 1 shows the overlap of the two sets of publications.
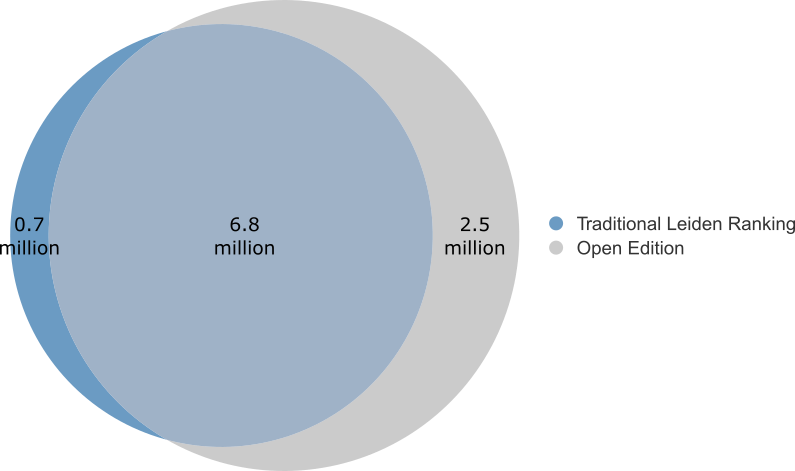
Of the 9.3 million publications included in the Open Edition, 2.5 million (27%) are not included in the traditional Leiden Ranking. The most important reason is that publications are not covered by the Web of Science citation indexes on which the traditional Leiden Ranking is based (i.e., Science Citation Index, Social Sciences Citation Index, and Arts & Humanities Citation Index). This explains why 1.7 million publications (19%) included in the Open Edition are not included in the traditional Leiden Ranking.
Conversely, of the 7.4 million publications included in the traditional Leiden Ranking, 0.7 million (9%) are not included in the Open Edition. There are several reasons for this. Inconsistencies in publication years (e.g., a publication was published in 2017 according to OpenAlex, while it was published in 2018 according to Web of Science) are an important reason, explaining why 0.2 million publications (3%) are not included in the Open Edition while they are included in the traditional Leiden Ranking. However, the most important reason is missing affiliation data in OpenAlex. 0.3 million publications (4%) are not included in the Open Edition because of missing author affiliations in OpenAlex, showing that missing affiliation data is a weakness of OpenAlex.
We now provide a more detailed analysis for the 6.8 million publications that are included in both the traditional Leiden Ranking and the Open Edition. For each of the 1411 universities in the Leiden Ranking 2023, we calculated the percentage of the publications of the university in the traditional Leiden Ranking that are not assigned to the university in the Open Edition. Figure 2 shows this percentage for each university, sorted from the highest to the lowest percentage.
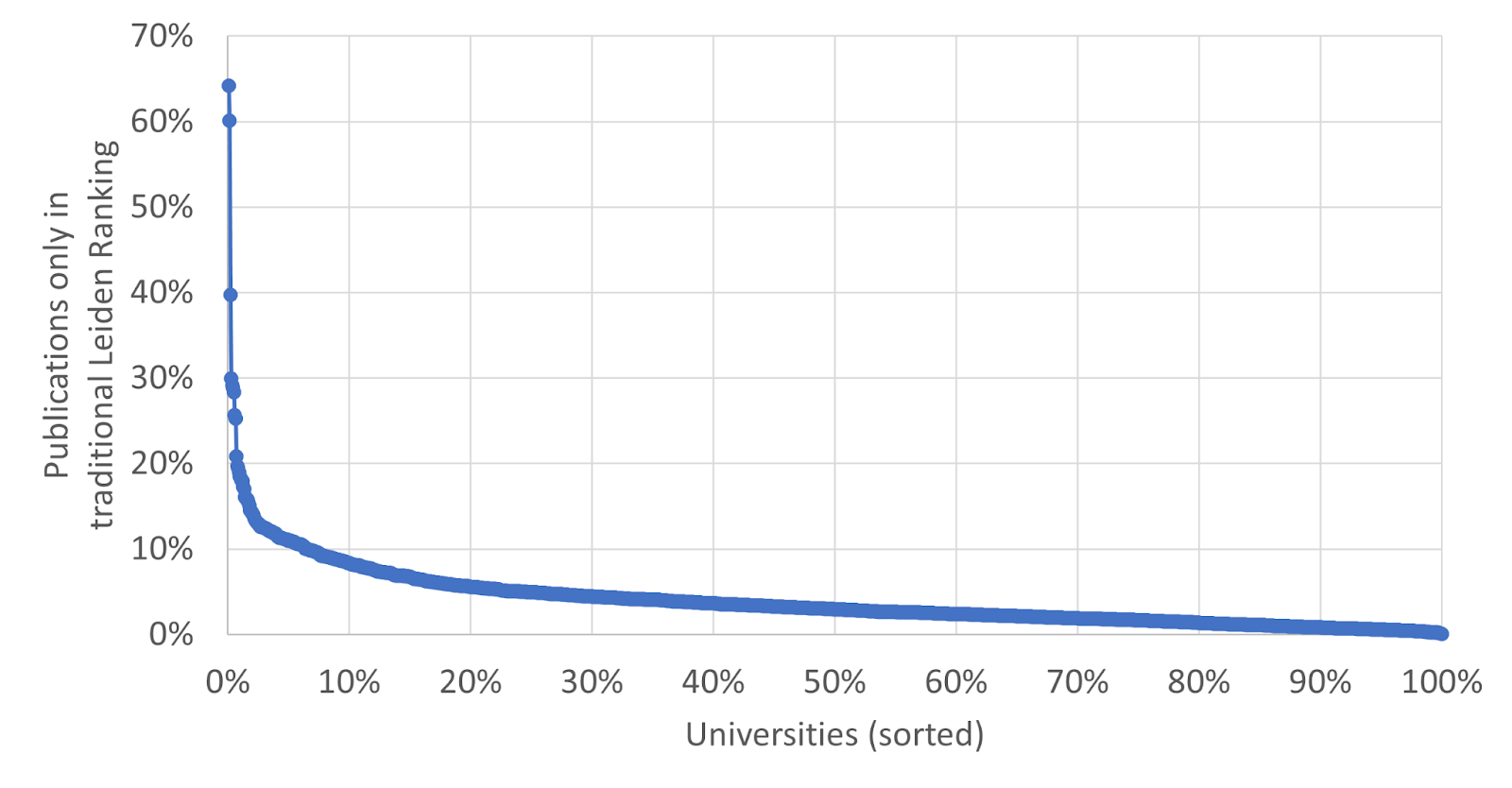
Figure 2 shows there are three universities for which more than 30% of the publications in the traditional Leiden Ranking are not assigned to the university in the Open Edition. In two cases this appears to be due to errors in the traditional Leiden Ranking, while in one case this seems to be due to errors in the Open Edition. There are 88 universities for which between 10% and 30% of the publications in the traditional Leiden Ranking are not assigned to the university in the Open Edition. For the other 1320 universities this is the case for less than 10% of the publications in the traditional Leiden Ranking.
We manually examined a random sample of 25 publications assigned to a university in the traditional Leiden Ranking but not in the Open Edition. For this small sample, we found that in 6 cases (24%) the assignment in the traditional Leiden Ranking was incorrect (because of an error made by either Web of Science or CWTS). In the other 19 cases (76%), an assignment incorrectly had not been made in the Open Edition (in most cases because of either a missing author affiliation in OpenAlex or an error in the mapping performed by OpenAlex from an affiliation string to a ROR ID).
Figure 3 offers the opposite perspective of Figure 2. For each of the 1411 universities, we calculated the percentage of the publications of the university in the Leiden Ranking Open Edition that are not assigned to the university in the traditional Leiden Ranking. These percentages are shown in Figure 3, again sorted from highest to lowest.
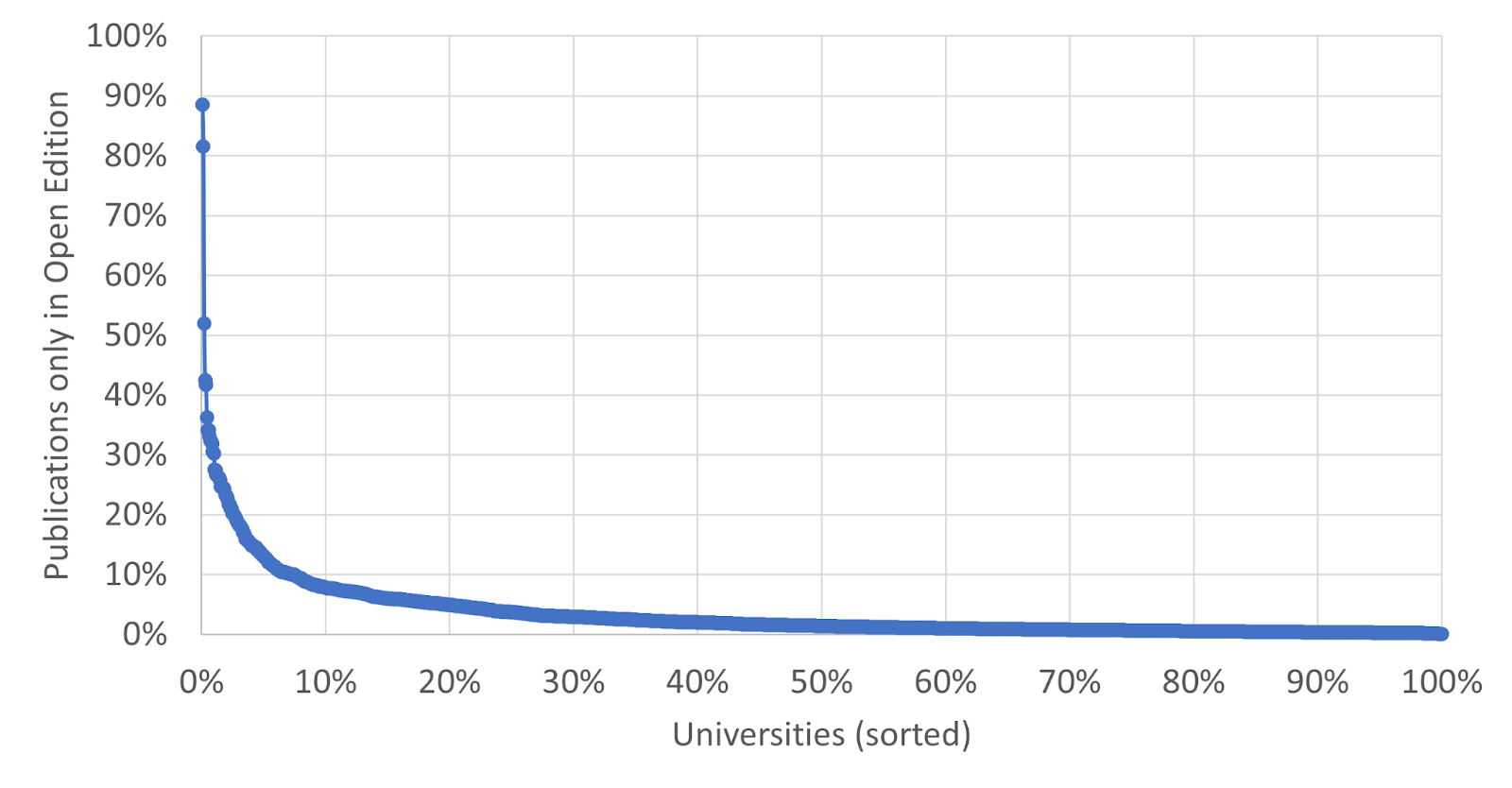
As Figure 3 shows, there are 14 universities for which more than 30% of the publications in the Open Edition are not assigned to the university in the traditional Leiden Ranking. In about two-thirds of the cases this appears to be due to errors in the Open Edition, while in the other cases this seems to be due to errors in the traditional Leiden Ranking. There are 91 universities for which between 10% and 30% of the publications in the Open Edition are not assigned to the university in the traditional Leiden Ranking. For the other 1306 universities this is the case for less than 10% of the publications in the Open Edition.
In a manual analysis of a random sample of 25 publications assigned to a university in the Open Edition but not in the traditional Leiden Ranking, we found that in 19 cases (76%) the assignment in the Open Edition was incorrect (in most cases because of an error in the mapping performed by OpenAlex from an affiliation string to a ROR ID). In the other 6 cases (24%), an assignment incorrectly had not been made in the traditional Leiden Ranking (for a variety of reasons).
In summary, for publications included in both the traditional Leiden Ranking and the Open Edition, our findings show that for most universities the data curation yields similar results in the two editions of the ranking. When there are differences, errors are about three times more likely in the Open Edition than in the traditional Leiden Ranking.
Room for improvement
The bibliometric community has extensive experience with the centralized and closed model for data curation. Over the years, databases such as Web of Science, Scopus, and Dimensions have made considerable investments in this model. Research organizations have also made large investments in it, both by paying to get access to the above-mentioned databases and by helping these databases improve their data (e.g., by reporting data quality problems, such as publications that are assigned to an incorrect organization). Likewise, by performing extensive curation of affiliation data for the traditional Leiden Ranking based on Web of Science data, CWTS has also invested substantially in a mostly centralized approach to data curation.
The bibliometric community has less experience with the decentralized and open model for data curation. Nevertheless, the results presented above show that the quality of affiliation data obtained through a more decentralized approach is already quite good. Moreover, there are lots of opportunities to further improve the data quality. Different actors can contribute to this in different ways:
- OpenAlex can contribute by making further improvements to the completeness of its affiliation data and to the machine learning algorithm it uses to map affiliation strings to ROR IDs.
- Research organizations can contribute by reporting data quality problems to OpenAlex. This will help OpenAlex to improve the quality of its data. Because OpenAlex data is open, anyone can identify problems in the data. This is different for closed databases, where only those who pay to get access to a database can identify problems.
- Publishers can contribute by attaching ROR IDs to author affiliations in publications and by depositing not only affiliation strings but also ROR IDs to Crossref. Several publishers, for instance Optica Publishing Group and eLife, have already started to do this. This enables OpenAlex to ingest ROR IDs from Crossref instead of inferring these IDs algorithmically.
- CWTS and other providers of bibliometric analytics can contribute by monitoring the quality of the affiliation data obtained from OpenAlex and by providing feedback to OpenAlex. If necessary, providers of bibliometric analytics can perform their own curation of affiliation data as a complement or substitute to the data curation performed by OpenAlex.
- All actors in the system can contribute by working together with ROR to make improvements to the registry. In particular, research organizations can make an essential contribution by providing authoritative curations on the relationships between institutions and their constituent parts.
The power of the decentralized and open model
We seem to have reached the limits of what can be achieved using the centralized and closed model for curating affiliation data. While for certain use cases the model may yield an acceptable data quality, the model is also highly resource-demanding, non-transparent, and inflexible.
Although the decentralized and open model is still in an early stage of development, it already yields a surprisingly good data quality. Moreover, by distributing the responsibility for different parts of the data curation process to different actors in the system, the model is more efficient and scalable than the centralized and closed model. On top of this, the decentralized and open model facilitates transparency and accountability, and offers the flexibility needed to address different use cases that require different choices to be made in the data curation process. Finally, the decentralized and open model ensures that investments in data curation benefit the global academic community instead of increasing the value of proprietary data sources.
By opening up the Leiden Ranking, we are moving toward a powerful new model for curating affiliation data. We invite universities to critically examine the affiliation data used in the Leiden Ranking Open Edition. Feedback from universities will help to further develop the decentralized and open model for data curation and to realize the highest possible data quality.
We thank colleagues at the Curtin Open Knowledge Initiative (COKI), Sesame Open Science, OurResearch, SIRIS Academic, and Sorbonne University for valuable feedback on a draft version of this blog post.
Header image: Henry Dixon on Unsplash
0 Comments
Add a comment